32. Finite Automata and Regular Expressions#
In this notebook, we will look at two closely related concepts: finite automata and regular expressions.
Finite automata (FA) are an abstract concept, but often have real-world counterparts. FA contain a number of states that a given system may have. Among the different states exist transitions that allow the system to move from one state to another.
One example is the traffic lights at a intersection. Below we have Main Street intersecting with First Avenue. Two sets of traffic lights - \(L_A\) and \(L_B\) exist. Behind the scenes, four states exist for this “system”. \(S_0\) allows traffic on First Avenue to have the right of way. If a transition occurs - \(\overline{T_A}\) - either from a sensor or timer), then the system to move state \(S_1\) where the light becomes yellow. After a timer finishes, the system then moves to \(S_2\).

Formally, a finite automata is a 5-tuple \((S,\Sigma,\delta,s_0,A)\) where
\(S\) is a finite set of states. \(s\) is a particular state. \(s \in S\)
\(\Sigma\) is a finite set of symbols (i.e., the alphabet). \(x\) is an input symbol. \(x \in \Sigma\)
\(\delta\) : \( S \times \Sigma \rightarrow S\) is the transition function. The inputs to this function are the current state \(s\) and the current input symbol \(x\), the result is the resulting state \(s_n\).
\(s_0\) is the starting state for the finite automata.
\(A\) is the set of accepting states for the automata. If the automata is in one of these states after reading all of the input, then the automata outputs “yes” and accepts the input. If the automata is not in one of these states after consuming the input, the output is “no” and the input is rejected. \(A \subseteq S\)
wc is Linux/Unix command line program that can provide counts of the number of characters, words, and newlines within a file.
One way that we can represent the logic within this program is through a finite automata. In this scenario, we have two states - is the program currently processing a characters inside a word or outside (not in) a word. Three groups of characters exist: \(C_N\) - a new line, \(C_{notword}\) - a character that cannot form a word (e.g., space or tab), and \(C_{word}\) - characters that can be part of a word.
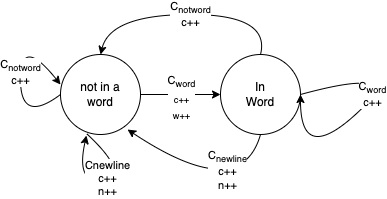
If the system is in the “not in a word” state and sees
\(C_N\): increment the character and new line counts, stay in “not in a word” state
\(C_{notword}\): increment the character count, stay in “not in a word” state
\(C_{word}\): increments the character and word counts, move to the word state
If the system is in the “word” state and sees
\(C_N\): increment the character and new line counts, move to the “not in a word” state
\(C_{notword}\): increment the character count, move to “not in a word” state
\(C_{word}\): increments the character count, stay in the word state
Other real world examples include vending machines (tracking coins received), elevators (current location, requested floors), and combination locks.
We can also use FA to model web applications. We can consider the current page of a web application to be a “state”. Transitions, then are the movements we take in moving from one page to another page. As with the wc example, we can augment the transitions to perform different activities.
Based upon the theoretical concepts of finite automata, we have regular expressions. Through a powerful notational grammar, regular expressions can find simple and complex text patterns. We’ll also see at the end of this notebook how we can go between finite automata and regular expressions.
In the Strings notebook, we learned how to to perform basic searches for text within Strings.
For example -
1line = "can we search for the specified value in the string?"
2print("value" in line)
3print(line.find("value"))
True
32
Quite often, though, we will want to search patterns of text rather than specific text strings. These patterns include things like phone numbers, email addresses, URLs, and zip codes. Suppose you were told to find all email address on a large number of web pages. How could you perform the search?
Regular expressions are sequences of character patterns matched against a string. We can use regular expressions to test for the presence of a pattern, extract the matched text, or replace text with another pattern. Practically, we use regular expressions for several tasks:
Extracting data from unstructured text
Validating web forms and other sources of input data before processing
Searching for protected information such as social security numbers in documents.
Cleaning data
Syntax or other keyword highlighting
Commonly, we refer to regular expressions as “regexes”.
To use regular expressions with Python, import the re module
1import re
As an initial example, we will repeat the previous search
1line = "can we search for the specified value in the string?"
2m = re.search('value',line)
3print("Type returned:",type(m))
4print("Value matched:",m.group())
5print("String tested:",m.string)
6print("Regular Expression:",m.re)
7print("Start position of the match:",m.start())
8print("End position of the match:",m.end())
Type returned: <class 're.Match'>
Value matched: value
String tested: can we search for the specified value in the string?
Regular Expression: re.compile('value')
Start position of the match: 32
End position of the match: 37
As you can see in the example, the regular expression search returns more information than just a Boolean. The return type is a Match object. m.group() provides the value that matched the regular expression.
The basic approach regular expressions following search for a string:
Take the first character of the regular expression (pattern).
Starting scanning a string from the start to the end. When the first character from the string matches, start consuming characters from both the string and the regular expression.
If the pattern has been consumed (everything has matched between it and the portion of the string being evaluated), then a successful match has occurred and the Matched object is returned.
If the pattern was not consumed, then the process is reset and the search continues after the next character from step #2.
Without any special metacharacters, sequences of characters match just the sequence. For example “abc” matches any substring of “abc” in a string using the re.search() method. The example above uses this sequencing pattern. However, we will create much more complex patterns that can repeat characters, alternate characters, choose characters from sets of characters, and more.
32.1. Basic Methods#
Four primary methods exist for regular expressions: more details
search()returns the first match of a regular expression with a string.findall()returns a list of all the substrings that matched the regular expression in order of their occurrence.split()splits a string at points where the pattern occurs and returns a list of the resulting piecessub()replaces matched patterns with a replacement string.
32.1.1. search#
As previously shown, search returns the first match of a regular expression with a string.
1line = "It was the best of times, it was the worst of times, it was the age of wisdom"
2m = re.search("was",line)
3if m:
4 print(m.start(),m.group())
3 was
It is not possible to specify a starting index with re.search(). We either need to alter the search string to remove the initial match or use alternative mechanism to find all of the matches.
32.1.2. findall#
findall() returns a list of a substrings that matched the pattern within the string.
1result = re.findall("was",line)
2print(type(result))
3print(result)
<class 'list'>
['was', 'was', 'was']
Unfortunately, the findall() method only returns a list of strings. If we need more details, Python offers a similar method, finditer() that returns the “findall” result as an iterable where each element is a Match object.
1for m in re.finditer("was",line):
2 print(m.start(), m.group())
3 was
29 was
56 was
32.1.3. split#
split() allows us to split a string by a particular pattern. Before in the string.split(), we could only split by another string. (Just pretend we have a more complex example.)
1result = re.split("was",line)
2print(type(result))
3print(result)
<class 'list'>
['It ', ' the best of times, it ', ' the worst of times, it ', ' the age of wisdom']
32.1.4. sub#
sub() allows us to replace patterns with different values
1result = re.sub("was","is",line)
2print(result)
It is the best of times, it is the worst of times, it is the age of wisdom
32.2. Patterns#
As alluded to in a prior code example, we intentionally used simple patterns to demonstrate the basic tasks (methods) that we can perform with regular expressions. With that understanding, we will now start to tackle creating more complex patterns with regular expressions. In many ways, regular expressions are a language themselves, although not as powerful as Python or other general purpose programming languages.
32.2.1. Metacharacters#
Typically, regular expressions contain special characters that function as operators or other special instructions.
Metacharacter |
Purpose |
|---|---|
[ ] |
Defines a custom character class |
{ } |
Used to define quantifiers for a range of a subpattern to repeat |
( ) |
Defines a grouping which allow us to extract multiple parts out of a string at once |
\ |
Used to escape metacharacters as well as to use pre-defined character classes |
* |
Matches zero or more occurrences of the previous character or grouping |
+ |
Matches one or more occurrences of the previous character or grouping |
? |
Matches zero or one occurrence of the previous character or grouping |
. |
Matches any character |
| |
Or symbol |
^ |
Matches the start of the string |
$ |
Matches the end of the string |
As we go through the following sections, we see how these various metacharacters are applied in regular expressions.
32.2.2. Predefined Character Classes#
Python defines a number of predefined character classes for our convenience. Notice that for each of these groups, the “not” (inverse) class is also defined.
Character Class |
Matches |
|---|---|
\d |
A single digit (e.g., 0-9) Includes Unicode Characters in the ‘Number, Decimal Digit’ Category) |
\D |
A single character that is not a digit |
\w |
Any word character (i.e., alphanumeric) |
\W |
Any non-word (non-alphanumeric) character |
\s |
Any whitespace character (space, tab, newline, etc.) |
\S |
Any non-whitespace character. |
\b |
A word word boundary (i.e., the start or end of a word). |
\B |
A non-word boundary |
1# The special characters are the arabic representation for 9 and 2.
2# The regular expression matches any sequence of continuous digits (one or more)
3m = re.search("\d+","Here are some non ASCII digits ٩٢. Where they found?")
4print(m)
5
6# This regular expression returns all continuous nondigit strings.
7print(re.findall("\D+","Here are some non ASCII digits ٩٢. Where they found?"))
<re.Match object; span=(31, 33), match='٩٢'>
['Here are some non ASCII digits ', '. Where they found?']
<>:3: SyntaxWarning: invalid escape sequence '\d'
<>:7: SyntaxWarning: invalid escape sequence '\D'
<>:3: SyntaxWarning: invalid escape sequence '\d'
<>:7: SyntaxWarning: invalid escape sequence '\D'
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/717232355.py:3: SyntaxWarning: invalid escape sequence '\d'
m = re.search("\d+","Here are some non ASCII digits ٩٢. Where they found?")
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/717232355.py:7: SyntaxWarning: invalid escape sequence '\D'
print(re.findall("\D+","Here are some non ASCII digits ٩٢. Where they found?"))
As \b is a Python escape sequence, we have to escape the backslash (\) first or use a raw string.
1#finds the string "here" where it is a complete word.
2print(re.findall("\\bhere\\b","here are some non ASCII digits ٩٢. Where they found? here they are there"))
3
4# using the iteration and a raw string
5for m in re.finditer(r"\bhere\b","here are some non ASCII digits ٩٢. Where they found? here they are there"):
6 print(m.start(), m.group())
['here', 'here']
0 here
54 here
32.2.3. Custom Character Classes#
The metacharacters [ and ] allow use to define custom character classes, which are sets of characters to use in a pattern. For example, [aeiouy] specifies the lowercase vowel characters.
1line = "It was the best of times, it was the worst of times, it was the age of wisdom"
2result = re.sub("[aeiouy]","",line)
3print(result)
It ws th bst f tms, t ws th wrst f tms, t ws th g f wsdm
Within [], we can list characters individually or specify a range of characters by specifying the start character, a -, and then the end character. The range uses the ordering specified by the Unicode character set. You can specify multiple ranges. The behavior is different than the basic pattern of just sequences - we are stating match any one of the characters in this set, not the sequence of those characters.
Examples:
[abc]matches any of the characters a, b, or c.[a-z]matches all lowercase ASCII letters[0-9]matches all ASCII digits[0123456789]also matches all ASCII digits (semantically equivalent to[0-9])[a-zA-Z]matches all ASCII letters
1for m in re.finditer("[a-zA-Z]","T3w^#s"):
2 print(m.start(), m.group())
0 T
2 w
5 s
With the exception of \, ^, and ], metacharacters are not active inside of custom character classes. I.e., you can include the other metacharacters without escaping them. ^ is only active if the first character.
1# Demonstrates the need to escape \ and ], but not the other metacharacters
2for m in re.finditer("[a-z$A-Z^[\]]","T[3w^#s$]"):
3 print(m.start(), m.group())
0 T
1 [
3 w
4 ^
6 s
7 $
8 ]
<>:2: SyntaxWarning: invalid escape sequence '\]'
<>:2: SyntaxWarning: invalid escape sequence '\]'
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/2379002585.py:2: SyntaxWarning: invalid escape sequence '\]'
for m in re.finditer("[a-z$A-Z^[\]]","T[3w^#s$]"):
You can also negate (complement) a character class by starting the regular expression with ^. For example, [^abc] matches any character except ‘a’, ‘b’, or ‘c’. If ^ is included in any other position than the first, then the symbol does not have any special meaning and just matches the character ‘^’.
1# Demonstrates negating/complementing the previous example
2for m in re.finditer("[^a-z$A-Z^[\]]","T[3w^#s$]"):
3 print(m.start(), m.group())
2 3
5 #
<>:2: SyntaxWarning: invalid escape sequence '\]'
<>:2: SyntaxWarning: invalid escape sequence '\]'
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/3691761921.py:2: SyntaxWarning: invalid escape sequence '\]'
for m in re.finditer("[^a-z$A-Z^[\]]","T[3w^#s$]"):
32.2.4. Quantifiers#
Creating patterns one character at a time can quickly become cumbersome. Fortunately, with regular expressions, we multiple ways to specify how many times a character (or an expression) should repeat.
The * quantifier specifies that the expression should repeat. As an example, consider finding names within a string. One possibility would by to find an uppercase character followed by zero or more lower cases characters. We can define that regular expression as [A-Z][a-z]*.
1for m in re.finditer("[A-Z][a-z]*","Sally sells seashells at Sandy Beach. I like her inventory."):
2 print(m.start(), m.group())
0 Sally
25 Sandy
31 Beach
38 I
By using the + operator, we specify that the character (or expression) repeats one or more times.
1for m in re.finditer("[A-Z][a-z]+","Sally sells seashells at Sandy Beach. I like her inventory."):
2 print(m.start(), m.group())
0 Sally
25 Sandy
31 Beach
The ? operator specifies that the previous character (or expression) should have zero or one occurrences.
In the following example, we make the uppercase letter optional, so this regular expression will find any words consisting of an optional uppercase ASCII letter followed by one ore more lowercase ASCII letters.
1for m in re.finditer("[A-Z]?[a-z]+","Sally sells seashells at Sandy Beach. I like her inventory."):
2 print(m.start(), m.group())
0 Sally
6 sells
12 seashells
22 at
25 Sandy
31 Beach
40 like
45 her
49 inventory
The * and + by default are greedy characters - they attempt to consume as many matching characters as possible. You can add the ? operator after them to match as few characters as possible.
1for m in re.finditer("[A-Z][a-z]+?","Sally sells seashells at Sandy Beach. I like her inventory."):
2 print(m.start(), m.group())
0 Sa
25 Sa
31 Be
With { }, we can specify the number of times a character should repeat - either a fixed number or as a range from a minimum number of occurrences to a maximum number of occurrences.
For example, to match US Zip Codes, use [0-9]{5}. We’ll also apply a word boundary to avoid partial word matches.
1for m in re.finditer(r"\b[0-9]{5}\b","1234 12345 123456"):
2 print(m.start(), m.group())
5 12345
To match patterns with a range length, we can use {m, n}. For example, finding words between 4 and 6 characters in length (and, again, using the word boundary to avoid partial matches):
1for m in re.finditer(r"\b\w{4,6}\b","Sally sells seashells at Sandy Beach. I like her inventory."):
2 print(m.start(), m.group())
0 Sally
6 sells
25 Sandy
31 Beach
40 like
32.2.5. Other pattens#
abcmatches the literal value “abc”(expr)matches the literal value withinexpr, but this also allows us to apply quantifiers to the expressions.expr1|expr2matchesexpr1orexpr2^matches the start of string$matches the end of string
1# demonstrates sequencing. any vowel followed by ll
2for m in re.finditer("[aeiouy]ll","Sally sells seashells at Sandy Beach. I like her inventory."):
3 print(m.start(), m.group())
1 all
7 ell
17 ell
1# find repeating patterns of "ab"
2for m in re.finditer("(ab)+","Sally abababab abba aaabbbaaa aaaa bababab"):
3 print(m.start(), m.group())
6 abababab
15 ab
22 ab
36 ababab
1# test that a string is 6-10 characters in length and only consists of "word" characters
2test_strings = ["hello", "python", "crumble","superfragilistic"]
3for word in test_strings:
4 m = re.search("^\w{6,10}$",word)
5 if m:
6 print(m.start(),m.group())
7 else:
8 print("No match:",word)
No match: hello
0 python
0 crumble
No match: superfragilistic
<>:4: SyntaxWarning: invalid escape sequence '\w'
<>:4: SyntaxWarning: invalid escape sequence '\w'
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/2114968397.py:4: SyntaxWarning: invalid escape sequence '\w'
m = re.search("^\w{6,10}$",word)
1colors="red|blue|green|yellow|white|black|purple"
2for m in re.finditer(colors,"The little red corvette drove fast down the black asphalt."):
3 print(m.start(), m.group())
11 red
44 black
32.3. Flags#
You can specify several different flags to change how regular expressions function.
Most notably, re.ASCII limits the predefined classes to ASCII characters only rather than the full set of Unicode characters. re.IGNORECASE makes the regular expression pattern match case insensitive.
1colors="red|blue|green|yellow|white|black|purple"
2for m in re.finditer(colors,"The little RED corvette drove fast down the BlacK asphalt.",flags=re.IGNORECASE):
3 print(m.start(), m.group())
11 RED
44 BlacK
1# The special characters are the arabic representation for 9 and 2.
2# The regular expression matches any sequence of continuous digits (one or more).
3# However, we are limiting the character set now to just ASCII
4m = re.search("\d+","Here are some non ASCII digits ٩٢. Where they found?",flags=re.ASCII)
5print(m)
6m = re.search("\d+","Here are some ASCII digits 123. Where they found?",flags=re.ASCII)
7print(m)
None
<re.Match object; span=(28, 31), match='123'>
<>:4: SyntaxWarning: invalid escape sequence '\d'
<>:6: SyntaxWarning: invalid escape sequence '\d'
<>:4: SyntaxWarning: invalid escape sequence '\d'
<>:6: SyntaxWarning: invalid escape sequence '\d'
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/1909783365.py:4: SyntaxWarning: invalid escape sequence '\d'
m = re.search("\d+","Here are some non ASCII digits ٩٢. Where they found?",flags=re.ASCII)
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/1909783365.py:6: SyntaxWarning: invalid escape sequence '\d'
m = re.search("\d+","Here are some ASCII digits 123. Where they found?",flags=re.ASCII)
32.4. Compiling#
Behind the scenes, Python compiles regular expressions and caches those results. However, by pre-compiling your regular expression, you minimize that overhead cost when the time comes to use the regular expression. To compile a regular expression, use re.compile(). You can then use use the same methods as before.
1pattern = re.compile("red|blue|green|yellow|white|black|purple",flags=re.IGNORECASE)
2for m in pattern.finditer("The little RED corvette drove fast down the BlacK asphalt."):
3 print(m.start(), m.group())
11 RED
44 BlacK
32.5. Capturing Group Values#
In addition to group parts of regular expression, we can use groups to extract information from different portions of the matched string.
Use the group() method, we can pass an argument to specify which group number to return. Groups are numbered from left to right starting at 1. Group 0 returns the entire match
1phone_pattern = re.compile("\((\d\d\d)\)(\d\d\d)-(\d\d\d\d)") # matches a US Phone number formatted (xxx)xxx-xxxx
2m = phone_pattern.search("My phone number is (919)867-5309 and my name is Jenny")
3if m:
4 print(m.group()) # entire substring matched
5 print(m.group(1)) # area code
6 print(m.group(2)) # exchange
7 print(m.group(3)) # line number
(919)867-5309
919
867
5309
<>:1: SyntaxWarning: invalid escape sequence '\('
<>:1: SyntaxWarning: invalid escape sequence '\('
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/84562273.py:1: SyntaxWarning: invalid escape sequence '\('
phone_pattern = re.compile("\((\d\d\d)\)(\d\d\d)-(\d\d\d\d)") # matches a US Phone number formatted (xxx)xxx-xxxx
For a more complicated regular expression, the following URL matches an email address:
1urlpattern=re.compile("([a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+)@([a-zA-Z0-9]([a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(\.[a-zA-Z0-9]([a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*)",flags=re.IGNORECASE)
2m = urlpattern.search("from: clark.kent@superheros.org <Clark Kent>")
3if m:
4 print(m.group()) # entire substring matched
5 print(m.group(1)) # "name"
6 print(m.group(2)) # domain
clark.kent@superheros.org
clark.kent
superheros.org
<>:1: SyntaxWarning: invalid escape sequence '\.'
<>:1: SyntaxWarning: invalid escape sequence '\.'
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/959346524.py:1: SyntaxWarning: invalid escape sequence '\.'
urlpattern=re.compile("([a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+)@([a-zA-Z0-9]([a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(\.[a-zA-Z0-9]([a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*)",flags=re.IGNORECASE)
32.6. Replacing substrings#
Earlier, we should an example of using a regular expression to perform matching and then replacing with a string. Here’s a similar example, but compiling the regular expression first.
1colors="red|blue|green|yellow|white|black|purple"
2color_pattern = re.compile(colors)
3line = color_pattern.sub("some color","The little red corvette drove fast down the black asphalt.")
4print(line)
The little some color corvette drove fast down the some color asphalt.
By using groups, we can make more complex substitutions. With the replacement string, the Python interpreter processes any backslash escape sequences - this includes the standard escapes such as \t and n for tab and newline. However, we can also create “backreferences” that corresponding to grouping that was match. These references start with a a backslash \ and then the number of the corresponding group from the regular expression. In the following example, we block out a portion of the phone number
1phone_pattern = re.compile("\((\d\d\d)\)(\d\d\d)-(\d\d\d\d)") # matches a US Phone number formatted (xxx)xxx-xxxx
2line = phone_pattern.sub(r"(\1)XXX-\2","My phone number is (919)867-5309 and my name is Jenny")
3print(line)
My phone number is (919)XXX-867 and my name is Jenny
<>:1: SyntaxWarning: invalid escape sequence '\('
<>:1: SyntaxWarning: invalid escape sequence '\('
/var/folders/f0/69wncpqd02s3j1r_z5sfddd00000gq/T/ipykernel_69011/3734563442.py:1: SyntaxWarning: invalid escape sequence '\('
phone_pattern = re.compile("\((\d\d\d)\)(\d\d\d)-(\d\d\d\d)") # matches a US Phone number formatted (xxx)xxx-xxxx
These notebooks make use of markdown to provide formatting such as underlines, italics, tables, etc. In markdown, using an underscore signifies to put a phrase in italics. This examples searches for such phrases (e.g., ‘_hello_’) and converts the underscores to the html equivalent.
1p = re.compile('_(.*)_')
2p.sub(r'<i>\1</i>','Tom Clancy\'s book, _The Hunt for Red October_, launched a massive and lucarative career.')
"Tom Clancy's book, <i>The Hunt for Red October</i>, launched a massive and lucarative career."
32.7. Regular Expressions and Finite Automata#
As alluded at the start of this notebook, regular expressions and finite automata in most situations can handle equivalent patterns. Some of the extended features in different regular expression versions go beyond what automata can necessarily process.
The following automata simple matches the given letter a. Assume any character that’s not a goes immediately to an error state not shown on the diagram:
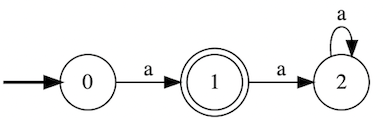
With this notation, we start at state 0. If an a is seen, we transition to state 1. The double circle represents an acceptance state. If more than one a is seen, we transition to state 2 and remain there - no path exists to return back to an acceptance state.
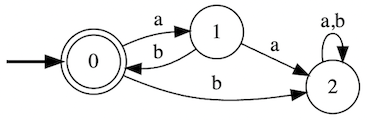
The follow finite automata represents the regular expression abc.

As before, we start in state 0. If an a is seen, we transition to 3. Any other characters from the starting state cause the transition to state 4, which functions as the error state and consumes all further input. From state 3, we transition to state 2 if we see a b and then from state 2 to state 1 (acceptance) if a c follows that b. Any other characters or more input sends us into the error state (4).
The next diagram represents the regular expression a+. We have to see at least one a. Any further a stay in the acceptance state. Any characters not present send the system to an unrepresented error state.

In this final example, we show the finite automata for (ab)*. As before, we start at state 0. However this state also functions as the acceptance state as we are looking for ab repeated zero or more times. From this state, a transitions to state 1. Then from state 1, b transitions back to state 0. Any unexpected output sends the system to 2 which consumes all further input.
These examples were generated at https://ivanzuzak.info/noam/webapps/fsm_simulator/
32.8. Resources#
A wealth of information exists for regular expressions as well as online tools to validate them.
Python Documentation:
Several websites with tutorials, sample regular expressions, and online testers
Books:
32.9. Suggested LLM Prompts#
Explain what finite automata are, their components (states, transitions, and alphabet), and how they are used to recognize patterns in strings. Provide examples of simple finite automata and the languages they recognize. Discuss the limitations of finite automata and the need for more powerful models like regular expressions.
Explain what regular expressions are and how they are used to describe patterns in strings. Demonstrate how regular expressions can be converted to equivalent finite automata and vice versa. Discuss the advantages of using regular expressions over finite automata in practical applications. Explore the relationship between regular expressions and formal language theory. Explain how regular expressions define regular languages and how they fit into the Chomsky hierarchy of formal languages. Discuss the limitations of regular expressions in representing context-free and context-sensitive languages.
Introduce the basic syntax of regular expressions in Python, including literals, character classes, quantifiers, and anchors. Provide examples of how to use these constructs to match different patterns in strings. Discuss the importance of understanding regular expression syntax for effective pattern matching.
Demonstrate how to perform various operations with regular expressions in Python, such as searching, matching, splitting, and substituting. Provide examples of how to use the
remodule and its functions (search,match,split,sub, etc.) to manipulate strings based on regular expressions.Discuss the performance implications of using regular expressions, particularly for complex patterns or large input strings. Introduce techniques for optimizing regular expressions, such as using non-greedy quantifiers, avoiding unnecessary backtracking, and leveraging precompiled patterns. Provide examples and benchmarks to illustrate the impact of optimization.
Demonstrate how regular expressions can be used in natural language processing tasks, such as tokenization, stemming, and named entity recognition. Provide examples of regular expressions for common NLP patterns (e.g., email addresses, URLs, dates, etc.) and discuss their limitations compared to more sophisticated NLP techniques.
Illustrate how regular expressions can be used for data extraction and cleanup tasks, such as parsing log files, cleaning up messy data, or extracting structured information from unstructured text. Provide examples of real-world scenarios and discuss best practices for using regular expressions effectively in these contexts.
32.10. Review Questions#
What is a finite automaton? Explain its components (states, transitions, and alphabet).
Explain what regular expressions are and how they relate to finite automata.
How can you use the
re.search()function in Python to find the first occurrence of a pattern in a string?What is the difference between the
re.match()andre.search()functions in Python’sremodule?Explain the purpose and usage of character classes in regular expressions.
How can you use quantifiers in regular expressions to match patterns with varying repetitions?
How can you use capturing groups in regular expressions to extract substrings from a match?
What is the purpose of the
re.sub()function in Python, and provide an example of its usage.How can you precompile and reuse regular expressions in Python to improve performance?
32.11. Exercises#
A typing mistake of those who learned typing on actual typewriters is to use two spaces after a period. With modern, proportionally-spaced fonts, this spacing is no longer needed. Write a function
eliminate_spaces(value)that condenses any multiple spaces into a single space and then returns the resulting value. Examples:” test “
returns” test “
"Once upon a time"
returns"Once upon a time"
You must use a regular expression within the method.
Write a function ‘extract_urls(text)’ that returns all URLs from the parameter. The urls should be in the format of
http[s]://value1.domain. Thevalue1can repeat one or more times.domainmust be lowercase ASCII Letters (e.g., a-z) and have between 2 and 6 characters in length. (Note: This last rule is just a convenience. The complete list of top level domain names is available at http://www.iana.org/domains/root/db)Write a function
convert_date_format(text)that converts a string (representing a date) in the format of “yyyy-mm-dd” to “dd-mm-yyyy”. You should use group to extract the values.Write a function
extract_ticker_symbols(text)that returns a set of all ticker symbols from a string. A ticker string must meet these conditions: 1) Be uppercase ASCII letter (A-Z). 2) Between 1 and 5 characters in length. 3) have a word boundary at the start and the end.Write a function
extract_adverbs(text)that finds all words ending in “ly”. The return value should be a list of tuples. Each tuple should have the start position, end position and the word (in that order).